文章利用模拟器训练进行自然语言处理、文本生成、知识图谱、强化学习和多任务学习
一、自然语言处理

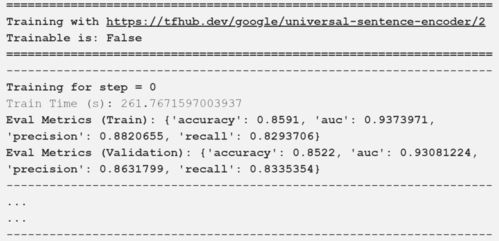
自然语言处理(LP)是人工智能领域的一个分支,它涉及到使用机器学习和深度学习技术来理解和处理人类语言。LP可以覆盖许多不同的任务,包括文本分类、情感分析、语音识别、命名实体识别等。
在模拟器训练中,我们可以通过构建特定类型的神经网络模型来处理自然语言数据。这些模型包括循环神经网络(R)、转换器(Trasformers)和长短期记忆网络(LSTM)等。训练过程中,我们将大量的语料库作为输入,通过优化算法调整模型参数,以最小化预测错误率。
二、文本生成
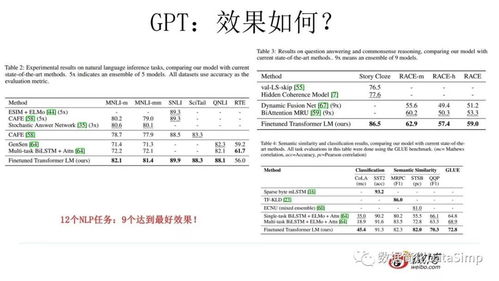
文本生成是LP的另一个重要应用,它可以根据给定的起始文本生成新的、与起始文本相关的文本。在模拟器训练中,我们通常使用循环神经网络(R)或转换器(Trasformers)模型进行训练。通过反向传播算法和梯度下降优化,模型可以学习到文本中的模式和规律,从而生成新的、合理的文本。
三、知识图谱

知识图谱是一种用于表示现实世界中各种实体和概念及其关系的数据模型。在模拟器训练中,我们可以通过图神经网络(Graph eural eworks, Gs)来处理知识图谱数据。Gs可以捕捉到图中节点和边的复杂关系,从而对实体间的关系进行建模。在训练过程中,我们使用特定的优化算法来调整G模型的参数,以最小化预测错误率。
四、强化学习
强化学习是一种通过智能体与环境交互来学习最优行为的机器学习方法。在模拟器训练中,我们通常会构建一个包含环境、智能体和反馈机制的模拟器,以支持强化学习算法的训练。智能体根据环境反馈进行行为选择,并通过与环境的交互不断更新其策略,以最大化累积奖励。在训练过程中,我们使用特定的强化学习算法,如深度确定性策略梯度(DDPG)或时间差分算法(TD3)等来优化智能体的行为策略。
五、多任务学习

多任务学习是一种机器学习方法,它可以让模型同时处理多个任务,并通过共享底层网络参数来提高模型的泛化能力。在模拟器训练中,我们可以构建一个多任务模型,使其同时处理多个LP任务,如文本分类、命名实体识别和情感分析等。通过共享参数,模型可以更好地捕捉到不同任务之间的共性,从而提高每个任务的性能。在训练过程中,我们使用特定的优化算法来调整模型参数,以最小化每个任务的损失函数。