语言模型训练、预训练模型、文本生成、评估指标、调试和优化、应用场景
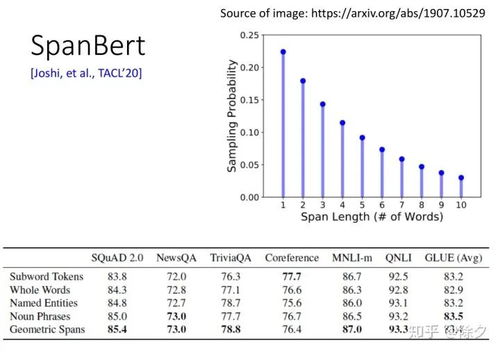
一、语言模型训练

语言模型训练是生成文章的重要步骤之一。在这个阶段,我们使用大量的文本数据来训练模型,使其能够学习语言的语法、词汇和语义等方面的知识。在训练过程中,我们通常使用深度学习算法来优化模型的参数,以便模型能够更好地理解和生成文本。
二、预训练模型
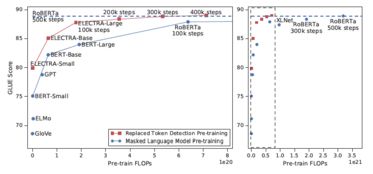
预训练模型是一种在大量无标签数据上训练的模型,它可以在后续任务中作为预训练的表示,为任务提供更强大的特征。在语言模型训练中,我们通常会使用预训练模型作为初始化的起点,然后针对特定的任务进行微调,以便模型能够更好地适应目标任务。
三、文本生成
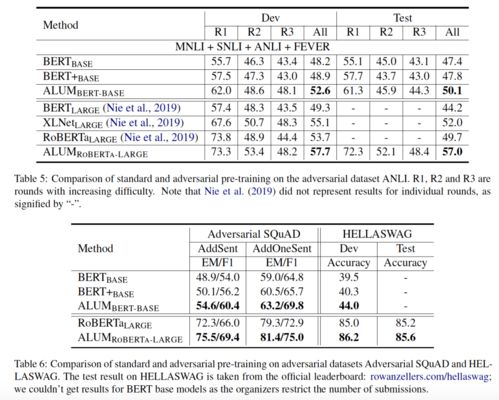
文本生成是语言模型的重要应用之一。我们可以通过给定一些输入文本,让模型生成与输入文本相关的输出文本。在生成文本时,我们需要注意以下几点:
1. 生成的文本要符合语言的语法和语义规则;
2. 生成的文本要与输入文本相关;
3. 生成的文本要有意义和可读性。
四、评估指标
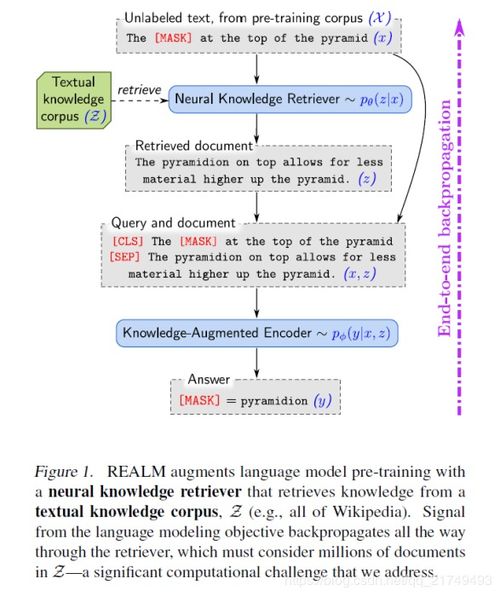
评估指标是衡量生成文章质量的重要标准。常用的评估指标包括:
1. 困惑度(Perplexiy):衡量模型生成文本的流畅度;
2. BLEU(Biligual Evaluaio Udersudy):衡量模型生成文本与真实文本的相似度;
3. ROUGE(Recall-Orieed Udersudy for Gisig Evaluaio):衡量模型生成文本与真实文本的语义相似度。
五、调试和优化
在语言模型训练过程中,我们经常需要调试和优化模型的参数和结构,以便提高模型的性能。常用的调试和优化方法包括:
1. 参数调整:通过调整模型的参数来优化模型的性能;
2. 结构调整:通过改变模型的结构来优化模型的性能;
3. 正则化:通过添加正则项来防止过拟合;
4. 早停法(Early Soppig):通过提前停止训练来防止过拟合。
六、应用场景语言模型的应用场景非常广泛,以下是一些常见的应用场景:
1. 自动翻译:语言模型可以用于不同语言之间的翻译;
2. 自动摘要:语言模型可以用于文本摘要的自动生成;
3. 情感分析:语言模型可以用于情感分析,判断文本的情感倾向;
4. 文本分类:语言模型可以用于文本分类,对文本进行分类标注;
5. 聊天机器人:语言模型可以用于构建聊天机器人,与用户进行对话交流。